作者:儒志楼 | 来源:互联网 | 2023-08-21 14:59
篇首语:本文由编程笔记#小编为大家整理,主要介绍了HDFS DataNode高密度存储机型的探索尝试相关的知识,希望对你有一定的参考价值。
前言
随着公司业务的发展,我们需要存储越来越庞大的数据来支撑公司业务的发展。这里就涉及到了数据存储能力的问题,需要存储的数据越多,其实意味着我们需要更多的机器来扩增HDFS集群存储的总capacity。但是机器数量的变多另外一方面带来的则是机器费用成本的巨大开销。我们如何在保证机器开销前提下,最大程度提升单机器的存储能力,这个就成为了一个集群维护人员需要思考和解决的问题。鉴于这个出发点,笔者最近在研究调研新一代具有更高存储能力的机型,这期间笔者做了大量的场景设置和性能测试来判断此机型是否能达到集群的要求。本文笔者来聊聊这方面的内容。
存储新机型的选型
首先,存储新机型引入的缘由上面已经提及过,是出于机器硬件方面的成本考虑的。因为本身公司内部HDFS集群的机器数量已经达到一个相当大的规模量级,每年这方面的开销已经相当巨大。随着集群数据的进一步扩增,我们考虑的下一个方案是通过增大机器磁盘的存储来提升集群的总磁盘能力而不是通过加原有机器的方式来。
目前在我们集群中主要使用的有2类存储机型:12(盘数)*5T以及12 * 10T的机型。这两种机型目前也已经渐渐无法满足于我们集群的要求。于是我们在调研尝试选择另外一种更大存储能力的机型,在初步机型的选择上,有下面两类方向:
- 方案一,盘数不变,大幅提升单盘存储空间,比如将12* 10T机型,增大到12*20T的机器。
- 方案二,单盘存储不变,盘数变多,比如24(盘) * 10T。
上面两种方式单论总capacity来看,他们的总capacity其实是一样的。那么这个时候我们考虑的就是哪种方式对系统服务的影响最小了。在我们的使用场景里,这些机器是给HDFS的DataNode使用的。这个机型选择问题就变成了何种机型更适用于DataNode使用的问题了。
了解过HDFS的同学应该知道,DataNode的数据管理是按照volume来区分的,这里的volume对应我们简单理解就是机器上面独立的存储盘。在上面两种机型中,方案一会大大增加每个volume里面存储的block数量,方案二则是会增加volume的数量。对于DataNode的影响来说,方案一的影响其实会更大一点,因为单volume存储的block越多,意味着DataNode在启动阶段需要花更多的时间来扫描volume上的数据块。这样会直接影响DataNode的启动速度。又因为DataNode启动采用的是多volume并行扫描块,方案二对于DataNode的影响就小多了。
另外从机器层面来说,单盘数据过多意味着更多的IO操作,在单盘IO处理能力不变的情况下,方案一会带来更大的IO压力。而多盘的情况则不一样了,因为盘与盘之间的IO是独立的,我们完全可以利用多盘的IO并行处理能力来满足数据的读写操作。
基于上述DataNode层面和系统层面的考虑,我们采用了方案二的机型作为调研的新机型。但是对于是否这种新的机型能满足生产集群DataNode性能的要求,我们还需要做大量的真实场景的测试才能知道最终答案。
新机型DataNode性能评估
新机型的数据快速填充
新机型选好后,下一阶段的工作主要是测试此类机型是否能够满足生产环境DataNode的性能要求。不过在性能测试之前,我们需要达到真实环境的要求,在这里我们的做法是将新机型机器直接加入到现有集群中。但这只是真实测试环境的第一步,我们的目标是能快速灌满这个机器的磁盘数据,使其数据使用量达到机器总量的80%,以此模拟出高数据负载的情况。
按照大磁盘机器的总capacity的80%估算,我们需要快速灌满大约200T的数据,我们想要在一周以内就能完成这个目标。如果只是依赖集群的正常业务的写操作来填满这个数据,一周内基本是不可能的。这里我们利用了现有Balancer的定向balance功能来做这里的灌数据行为。我们做了以下balance相关调整来达到日均50T的数据搬迁量:
- 将balance带宽设置到了800MB/s的速度。
- 将单节点可balance的size进行相应调整,增大到100GB。
- 部署新的Balancer进程来并行拷贝不同Federation namespace的数据。
- 写脚本每天动态生成source节点用以进行balance,因为我们采用的定点平衡做法会导致source node会很快被balance掉,我们需要每天都能生成一波新的需要balance的节点用来灌数据。
另外我们在灌数据的时候,发现balance速率还是会是不是的变慢,一开始我们怀疑瓶颈点可能在target节点,后来通过分析机器ioutil使用率发现是在source节点。以下面这个机器为例子:
01:17:59 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
01:18:02 AM sdm 3.00 0.00 74.67 24.89 0.00 0.22 0.44 0.13
01:18:02 AM sdk 4.67 2061.33 0.00 441.71 0.13 28.57 16.57 7.73
01:18:02 AM sde 26.67 1882.67 589.33 92.70 4.26 161.47 4.75 12.67
01:18:02 AM sdl 165.33 80962.67 0.00 489.69 6.76 42.79 6.01 99.33
01:18:02 AM sdh 231.00 115946.67 0.00 501.93 16.59 74.09 4.32 99.87
01:18:02 AM sdf 271.67 125538.67 12290.67 507.35 33.06 123.87 3.60 97.73
01:18:02 AM sdg 6.67 2152.00 0.00 322.80 0.02 4.10 4.60 3.07
01:18:02 AM sdc 182.67 91512.00 13.33 501.05 5.32 31.55 5.38 98.27
01:18:02 AM sdd 212.33 107181.33 58.67 505.05 14.84 72.10 4.66 98.93
01:18:02 AM sda 5.67 2122.67 0.00 374.59 0.03 6.94 6.59 3.73
01:18:02 AM sdb 268.67 134232.00 0.00 499.62 32.03 121.42 3.72 99.87
01:18:02 AM sdj 3.67 1877.33 0.00 512.00 0.02 5.18 4.73 1.73
01:18:02 AM sdn 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
01:18:02 AM sdi 7.67 2173.33 0.00 283.48 0.14 19.74 11.30 8.67
上面的机器总共有12块盘,当balance工具全速在跑的时候,我们看到只有大约5块盘是满负载状态在搬数据,其它剩余的盘其实蛮清闲的。这其实侧面反映的问题是balancer在选source block的时候没有做到足够的打散分布,才会出现这样的状况。关于这个问题,我们后来减小了balancer每次选择block的相关参数dfs.balancer.getBlocks.size,从默认的2GB改到512MB。因为每次选取的块的总size切分的更小了,后面选择到的块也就更加随机化了。
DataNode性能指标测试
在完成数据填充后,在新存储机型里我们已经有了一个比较真实的接近于集群实际数据存储的状态。下面我们做的事情就很简单了,收集,观察和对比DataNode本身的性能指标。
在这里我们主要挑选了DataNode目前和其性能息息相关的一些metric:
第一点,block操作相关的指标,能够直接反映出DataNode实际操作吞吐量,主要为下面四个指标:
- ReadBlockOpNumOps
- WriteBlockOpNumOps
- ReadBlockOpAvgTime
- WriteBlockOpAvgTime
- XceiverCount:Xceiver count能反映DataNode的忙碌程度
第二点,DataNode自身行为的相关指标,比如心跳汇报,块汇报,命令处理等等,这里主要有下面一些指标:
- HeartbeatsAvgTime
- BlockReportsAvgTime
- IncrementalBlockReportsAvgTime
- ProcessedCommandsOpAvgTime
第三点,更细粒度的IO操作行为指标,比如数据网络传输时间,数据写磁盘的时间等等,
- MirrorOutNumOps
- MirrorOutAvgTime
- FsyncNanosNumOps: 数据写到磁盘的数据.
- FsyncNanosAvgTime
- FlushNanosAvgTime: 刷数据到OS cache的时间
- FlushOrSyncNumOps
- FlushOrSyncAvgTime
- DropCacheBehindWritesAvgTime
还有其它一些行为指标,需要我们自己额外手动测试记录,这里主要有:
- DataNode启动时间,这里具体指的是块扫描完然后汇报给NameNode的时间。
- 节点完整Decommission的时间。
- Heap使用大小
- 总存储block数量
为了能够更加直观地对新机型和集群原有机型的metric作对比,我们专门做了一个Grafana的dashboard来展示metric指标,dashboard如下图示所示:
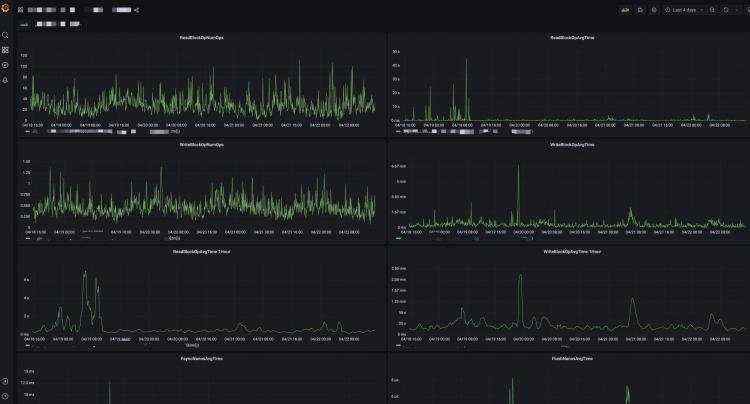
通过分析上述细粒度的DataNode性能指标,我们发现在大存储的机型下,DataNode block report的平均时间上升了非常之多。我们对此的一个解决办法是通过调整DataNode端的块spil参数(dfs.blockreport.split.threshold)使得块汇报能够按照盘粒度进行逐一汇报而不是按照整个节点一次性的汇报,以此来减轻block report对NameNode的压力。
在观察DataNode性能期间,我们额外发现了一个潜在的DataNode内存使用过量从而引发严重full GC的问题,后来发现这是一个社区的known issue HDFS-15621。
对于block读写操作量,这里其实还有另外一个隐藏的影响因素需要额外关注。目前NameNode内部对于数据的读写有考虑到DataNode的负载(Xceiver count数)情况,它会让client避免向那些高负载的机器上进行数据的读写(相关配置:dfs.namenode.read.considerLoad/dfs.namenode.replication.considerLoad)。因此为了能得到更加精准的读写block操作数,我们临时对新机型的机器进行了略过load检查的处理。
总结
通过上面的测试结果分析,我们基本能够得出一个比较准确的结果来衡量新机型是否能够满足实际DataNode性能的要求。以上就是本文分享的关于存储新机型的一个探索调研方案。




 京公网安备 11010802041100号
京公网安备 11010802041100号